
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 시각화
- 머신러닝
- 해석
- Oracle
- Deep Learning
- tensorflow
- 데이터베이스
- HeidiSQL
- 딥러닝
- keras
- 정확도
- 데이터
- python
- pythone
- 훈련
- 예측
- 파싱 오류
- Database
- sklearn
- 데이터전처리
- python기초
- 오라클
- MariaDB
- pandas
- 데이터 분석
- 데이터 수집
- 데이터 가공
- DB
- sql
- 회귀모델
- Today
- Total
코딩헤딩
Deep learning[딥러닝] 합성곱신경망(CNN; Convolutional Neural Network) 본문
<합성곱신경망(CNN; Convolutional Neural Network)>
- 이미지 분석에 주로 사용되는 대표적 계층
- 기존의 인공신경망에서의 이미지 분석 시에는 높이와 너비를 곱한 1차원을 사용하였다면,
CNN은 원형 그래로의 높이와 너비 차원을 사용함
- 전체 4차원의 데이터를 사용함
- 기존 이미지 문석 시 높이와 너비를 곱하여 사용하다 보면,
* 원형 그대로의 주변 이미지 공간 정보를 활용하지 못하는 단점이 있으며,
* 이러한 이유로 특정 추출을 잘 못하여, 학습이 잘 이루어지지 않는 경우가 발생함
- 이러한 기존 인공신경망 모델의 단점을 보완하여 만들어진 모델이 CNN임
* 원형 형태의 이미지 정보를 그대로 유지한 상태로 학습 가능하도록 만들어졌음
* 이미지의 공간정보를 이용하여 특징을 추출함
* 인접 이미지의 특징을 포함하여 훈련됨.
<합성곱 신경망(CNN)의 계층 구조>
1. 입력계층(Input Layer)
- 데이터 입력 계층(기존과 동일)
*2. 합성곱 계층(Convolutonal Layer, CNN 계층)
- 이미지의 특징을 추출하는 합성곱 계층이 여러 층으로 구성되어 있음
*3. 활성화 함수 계층(은닉계층; Activation Layer)
- 합성곱 계층의 출력에 대한 비선형성을 추가한 활성화 함수 ReLU와 같은 함수 적용
*4. 풀링 계층(Pooling Layer)
- 공간 크기를 줄이고 계산량을 가소시키기 위한 계층(중요 특징만 추출하는 계층)
- 풀링 방법으로 최대풀링(Max Pooling), 평균 풀링(Average Pooling)이 있음.
- 주로 Max Pooling이 사용됨
*5. 완전연결 계층 (은닉계층; Dense Layer)
- 추출된 특징을 이용하여 최종 예측을 수행하는 계층
- 이때는 기존의 방법과 동일하게 1차원 (높이 X 높이)의 전처리 계층(Plattern)을 사용하는 경우도 있음(인공신경망 모델과 동일한 계층 구조로 진행)
6. 출력 계층(Outer Layer)
- 죄종 예측이 이루어지는 계층
*** CNN에서는 2~5번의 계층구조가 일반적으로 사용됨,
- 나머지 계층은 기존과 동일한 계층
- 2~5번의 CNN계층은 여러 개 추가 가능
* 라이브러리
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
* 패션 이미지 데이터 읽어 들이기
keras.datasets.fashion_mnist.load_data()결과 :
((array([[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
.
.
.
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)결과 :
(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
* 4차원으로 만들기
train_input_4d = train_input.reshape(-1, 28, 28, 1)
train_input_4d.shape결과 : (60000, 28, 28, 1)
* CNN에서 사용하는 차원은 4차원
- (행, 높이, 너비, 채널)
- 채널 = 1 또는 3 (1은 흑백, 3은 컬러(RGB)라고 보통 칭한다.)
len(train_input_4d[0][0][0]), train_input_4d[0][0][0]결과 : (1, array([0], dtype=uint8))
* 정규화
* 픽셀 데이터 정규화
train_scaled = train_input_4d / 255
train_scaled.shape, train_scaled[1][0]결과 :
((60000, 28, 28, 1),
array([[0. ],
[0. ],
[0. ],
.
.
.
* 훈련 및 검증 데이터로 분리하기 => 8:2
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target,
test_size=0.2, random_state=42)
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)
print(test_input.shape, test_target.shape)결과 :
(48000, 28, 28, 1) (48000,)
(12000, 28, 28, 1) (12000,)
(10000, 28, 28) (10000,)
* 합성곱신경망(CNN) 훈련
model = keras.Sequential()
model결과 : <keras.engine.sequential.Sequential at 0x18cfae74070>
* CNN(입력 계층으로 추가)
model.add(keras.layers.Conv2D(kernel_size=3,
filters=32,
activation="relu",
padding="same",
strides=1,
input_shape=(28, 28, 1)))
<CNN>
- 데이터와 필터(filter)가 곱해진다고 해서 합성곱이라는 단어가 붙었음
- 이미지와 같은 2차원 데이터 분류에는 보통 2차원 합성곱 (Conv2D)이 사용됨
- 입력 계층으로 사용하는 경우에는 input_shape의 입력 차원 속성을 함께 사용
<kernel_size>
- 이미지를 훑으면서 특징을 추출하는 역할을 수행
- 필터가 사용할 사이즈 정의함
- kernel_size=3 => 필터가 사용할 사이즈 3행 3열을 의미함(3x3을 줄여서 3이라고 칭함)
- 커널 사이즈는 홀수로 정의함(3, 5가 주로 사용됨)
<filters>
- 커널사이즈의 행렬의 공간 1개에 대한 필터의 개수 정의
- 데이터를 훑으면서 특징을 감지함
- 필터의 값이 클수록 훈련속도가 오래 걸림
- 보통 32, 64가 주로 사용됨
- CNN계층을 여러 개 사용하는 경우에는 처음 CNN계층에는 작은 값부터 시작
=> 16, 32, 64, 128 정도가 주로 사용됨
<padding>
- 경계 처리 방식을 정의함
- 입력 데이터의 주변에 추가되는 가상의 공간을 만들 수 있음
- 처리 방식 : smae과 valid가 있음
* same : 패딩을 사용하여 입력과 출력의 크기를 동일하게 만들어서 훈련하고자 할 때 사용
: 주로 권장되는 방식
* valid : 패딩을 사용하지 않음을 의미함
<strides>
- 커널이 이미지 데이터를 훑을 때(특징 추출 시)의 스탭을 정의함
- 커널이 데이터 특징 추출 순서(행렬을 기준으로)
=> 왼쪽 상단에서 시작하여 오른쪽으로 이동하는 스텝 정의
=> 오른쪽 열을 다 훑고난 다음 아래로 이동하는 스탭 정의
- strides=1 : 오른쪽으로 1씩 이동, 아래로 1씩 이동을 의미함
* 폴링레이어(Pooling Layer)
model.add(keras.layers.MaxPool2D(pool_size=2, strides=2))풀링레이어(Pooling layer)
- CNN계층 추가 이후에 일반적으로 사용되는 계층
- CNN계층에서 추출된 특징들 중에 유효한 정보만을 추출하는 계층
- 머신러닝에서 주성분 분석(PCA)과 유사한 개념
- 이미지를 구성하는 픽셀들이, 주변에 필셀들끼리는 유사한 정보를 가진다는 개념에서 중복된 값이나 유사한 값들을 대표하는 값들 즉, 중요한 특징들만 추출하게 됨.
- 과적합 방지에 요율적으로 사용되며, 훈련 성능에 영향을 미치지 않는 전처리 계층임.
* MaxPool2D
- 사소한 값들은 무시하고 최댓값의 특징들만 추출하는 방식
- pool_size=2 : 2행 2열의 공간에 중요 특징들만 저장하라는 의미
- strides=2 : CNN에서 추출한 특징값들의 행렬을 오른쪽 2칸씩, 아래로 2칸씩 이동하면서 중요 특징값 추출하라는
의미 / 기본 디폴트값은 2 (생략가능)
- 풀링에서 가장 대표적으로 사용되는 방식음
* CNN계층 추가해 보기
model.add(keras.layers.Conv2D(kernel_size=3,
filters=64,
activation="relu",
padding="same",
strides=1))
model.add(keras.layers.MaxPool2D(pool_size=2, strides=2))
* 인공신경망 계층 추가(전처리 또는 은닉계층 + 출력계층)
###예측을 위해 중요 특징 데이터를 1차원(높이 X 너비)로 변환하기
model.add(keras.layers.Flatten())
### 은닉계층 추가
# - 활성화 함수 추가됨
model.add(keras.layers.Dense(100, activation="relu"))
### (전처리 계층) 드롭아웃 적용
model.add(keras.layers.Dropout(0.2))
### 출력계층 추가
model.add(keras.layers.Dense(10, activation="softmax"))
model.summary()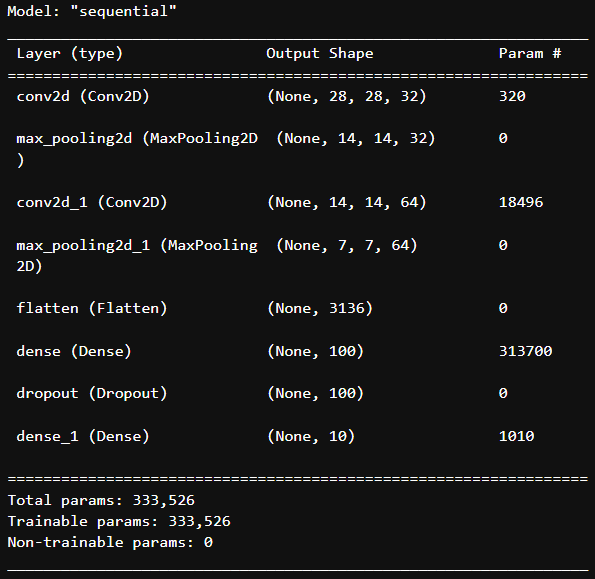
* 훈련 계층을 이미지로 시각화해보기
from tensorflow.keras.utils import plot_modelplot_model(model, show_shapes=True,
to_file="./model_img/CNN_Layer.png",
dpi=300)
* 계층모델 속성 정의하여 시각화 및 저장시키기
- show_shapes : 층의 형태를 세부적으로 표현(기본값은 False)
- dpi : 이미지 해상도
- to_file : 저장위치(기본값은 현재 실행 파일이 있는 위치와 동일한 곳에 저장됨)
* 모델 설정하기
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics="accuracy")
* 콜백함수 만들기 (자동화, 자동종료)
model_path = "./model/cb.h5"
checkpoint_cd = keras.callbacks.ModelCheckpoint(model_path, save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
checkpoint_cd, early_stopping_cb결과 :
(<keras.callbacks.ModelCheckpoint at 0x25de191a880>,
<keras.callbacks.EarlyStopping at 0x25de191a820>)
* 훈련시키기
history = model.fit(train_scaled, train_target,
epochs=20, verbose=1,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cd, early_stopping_cb])결과 :
Epoch 1/20
1500/1500 [==============================] - 57s 37ms/step - loss: 0.4780 - accuracy: 0.8291 - val_loss: 0.3212 - val_accuracy: 0.8813
Epoch 2/20
1500/1500 [==============================] - 51s 34ms/step - loss: 0.3108 - accuracy: 0.8873 - val_loss: 0.2700 - val_accuracy: 0.9006
Epoch 3/20
1500/1500 [==============================] - 53s 35ms/step - loss: 0.2636 - accuracy: 0.9044 - val_loss: 0.2506 - val_accuracy: 0.9066
* 훈련 20회만 수행한 후 "훈련과 검증에 대한 손실곡선과 정확도 곡선 시각화" 하기
* 시각화 하시
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.title("CNN Train vs Val Loss")
plt.plot(history.epoch, history.history["loss"])
plt.plot(history.epoch, history.history["val_loss"])
plt.grid()
plt.legend(["loss", "val_loss"])
plt.show()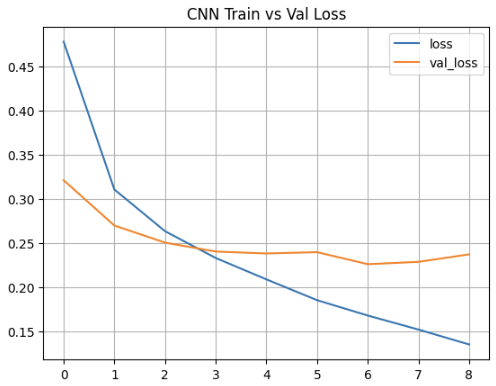
plt.title("CNN Train vs Val Accuracy")
plt.plot(history.epoch, history.history["accuracy"])
plt.plot(history.epoch, history.history["val_accuracy"])
plt.grid()
plt.legend(["acc", "val_acc"])
plt.show()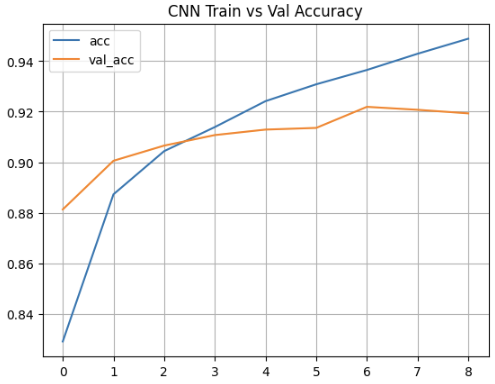
* 훈련 및 검증데이터 모델 성능 검증결과 확인
train_eval = model.evaluate(train_scaled, train_target)
val_eval = model.evaluate(val_scaled, val_target)
train_eval, val_eval결과 :
1500/1500 [==============================] - 19s 13ms/step - loss: 0.1167 - accuracy: 0.9572
375/375 [==============================] - 5s 12ms/step - loss: 0.2262 - accuracy: 0.9219
([0.11670560389757156, 0.9572499990463257],
[0.2262299656867981, 0.921916663646698])
* 훈련에 사용된 데이터를 이미지로 그려보기
val_scaled[0].shape결과 : (28, 28, 1)
* 이미지 데이터는 2차원으로 줄여서 그려야 한다.
val_scaled_0 = val_scaled[0].reshape(28, 28)
val_scaled_0.shape결과 : (28, 28)
* 이미지 한 개 그려보기
plt.imshow(val_scaled_0, cmap="gray_r")
plt.show()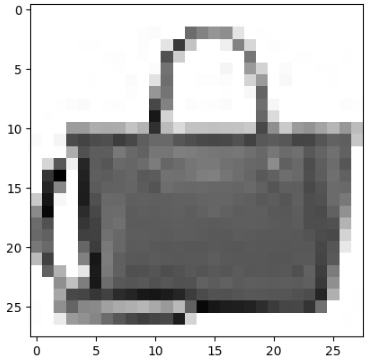
* 검증데이터 0번째 데이터를 이용해서 예측해 보기
- 예측 결괏값은 모델 출력계층의 출력크기(개수) 만틈 확률값으로 반환해 준다.
- 반환된 확률값 중 가장 큰 값의 "인덱스번호"가 종속 변수 값이 된다.
preds = model.predict(val_scaled)
preds[0]결과 :
array([1.62347510e-16, 4.14307207e-20, 5.02922866e-19, 2.80608470e-18,
2.37707541e-16, 1.09323620e-14, 1.86780228e-17, 3.84609116e-15,
1.00000000e+00, 1.19970355e-17], dtype=float32)
pred_max = tf.argmax(preds, axis=1).numpy()[0]
pred_max결과 : 8
* 그래프 시각화
plt.bar(range(10), preds[0])
plt.xticks(range(10))
plt.grid()
plt.show()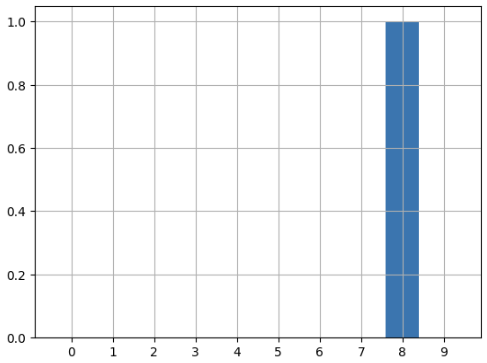
### 범주 명칭
classes = ["티셔츠", "바지", "스웨터", "드레스", "코드", "샌달", "셔츠", "스니커즈", "가방", "앵클부츠"]
classesimport numpy as np
print(np.argmax(preds))
print("실제값 :", classes[np.argmax(preds)])
print("예측값 :", classes[val_target[0]])결과 :
8
실제값 : 가방
예측값 : 가방
* 테스트 데이터로 최종 예측하기
테스트 데이터를 이용해서 예측한 후,
- 예측 결과 중 10개만 추출하여 => 예측이미지 출력, 예측값, 실제값을 각각 출력하기
for i in range(10):
plt.imshow(test_input[i], cmap="gray_r",)
plt.show()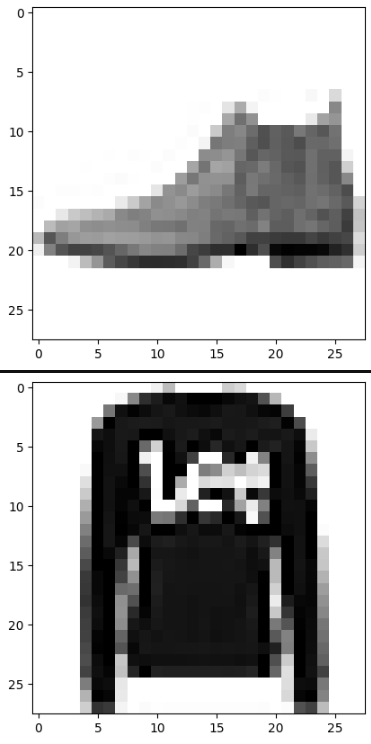
.
.
.
test_pred = model.predict(test_input)
test_pred결과 :
array([[0., 0., 0., ..., 0., 0., 1.],
[0., 0., 1., ..., 0., 0., 0.],
[0., 1., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 1., 0.],
[0., 1., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32)
pred_test = tf.argmax(test_pred, axis=1).numpy()[:10]
pred_test결과 : array([9, 2, 1, 1, 6, 1, 4, 6, 5, 7], dtype=int64)
for i in range(10):
plt.imshow(test_input[i], cmap="gray_r")
plt.show()
print(np.argmax(test_pred[i]))
print("실제값 :", classes[test_target[i]])
print("예측값 :", classes[pred_test[i]])결과 :
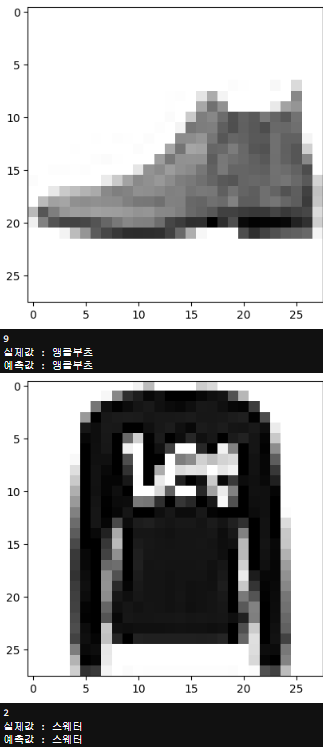
.
.
.
'머신러닝 | 딥러닝' 카테고리의 다른 글
| Deep learning[딥러닝] YOLO 객체탐지 네트워크 가중치 모델 사용 (1) | 2024.01.10 |
|---|---|
| Deep learning[딥러닝] YOLO 객체탐지 네트워크 기초 (0) | 2024.01.10 |
| Deep learning[딥러닝] RNN 응용 규칙기반 챗봇 (1) | 2024.01.09 |
| Deep learning[딥러닝] LSTM GRU (0) | 2024.01.08 |
| Deep learning[딥러닝] 심플순환신경망(simple RNN) (1) | 2024.01.08 |



