
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 해석
- sklearn
- Database
- 파싱 오류
- 회귀모델
- 훈련
- sql
- 예측
- 데이터 분석
- pythone
- Deep Learning
- 데이터베이스
- MariaDB
- python기초
- 데이터 수집
- 머신러닝
- 데이터 가공
- 딥러닝
- python
- 데이터
- 시각화
- 오라클
- 정확도
- DB
- HeidiSQL
- tensorflow
- Oracle
- keras
- 데이터전처리
- pandas
- Today
- Total
코딩헤딩
[웹 크롤링(web crawling)] 영화데이터시각화 4 (단어 빈도분석) 본문
워드클라우드를 만들기 위해서는 다음 라이브러리가 필요하다.
https://coding-heading.tistory.com/73
[파이썬 koNLPY] 한글 형태소 분석 라이브러리
- java기반으로 만들어진 라이브러리로 JDK 설치 및 환경설정 필요 1. 환경변수 등록 시작 > 검색창에 환경검색 > 시스템 환경 변수 편집클릭 왼쪽 화면이 뜬다. 2. JAVA_HOME JAVA_HOME의 경로는 JDK설치
coding-heading.tistory.com
* 라이브러리 정의하기
import pandas as pd
* 데이터넷 읽어 들이기
- 데이터 프레임 변수명 : df_org
df_org = pd.read_csv("./data/df_new.csv")
df_org
1. 긍정 및 부정에 대해서만 각각 데이터 필터링하기
* 긍정 리뷰 데이터 필터링
- 데이터프레임 변수명 : pos_reviews
pos_reviews = df_org[df_org["label"]==1]
pos_reviews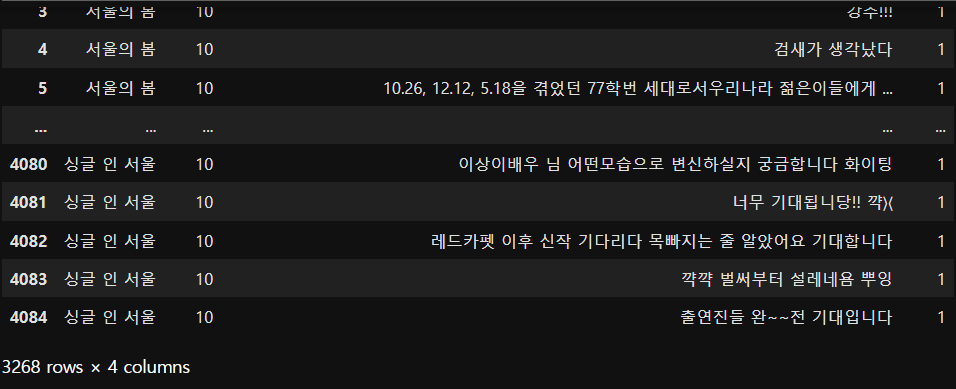
=> 전체 리뷰 4085건 중 긍정리뷰 총 3268건
* 부정 리뷰 데이터 필터링
- 데이터프레임 변수명 : neg_reviews
neg_reviews = df_org[df_org["label"]==0]
neg_reviews
=> 전체 리뷰 4085건 중 긍정리뷰 총 3268건, 부정리뷰 570건. 나머지는 기타.
2. 리뷰 데이터 전처리
- 긍정 및 부정 리뷰 데이터에서 한글 이외 모두 제거하기
### 정규표현식 라이브러리
import re* 긍정 및 부정 리뷰에서 한글 이외 모두 제거 처리하기
pos_reviews.loc[ : , "comment"] = [re.sub(r"[^ㄱ-ㅣ가-힣+]", " ", data)for data in pos_reviews["comment"]]
pos_reviewsneg_reviews.loc[ : , "comment"] = [re.sub(r"[^ㄱ-ㅣ가-힣+]", " ", data)for data in neg_reviews["comment"]]
neg_reviews--->> 정규표현식 라이브러리 활용.
3. 긍정 및 부정 리뷰 형태소 추출하기
* 형태소 분석 라이브러리
import jpype
- jpype : java 라이브러리를 python에서 사용할 수 있도록 도와주는 라이브러리
- konlpy는 java로 만들어진 라이브러리
from konlpy.tag import Okt - Okt : 한국어 형태소 분석 라이브러리
- Okt(Open Korean Text) : 대표적 한글 형태소 분석기
* 긍정 및 부정 리뷰 데이터에서 --> 명사 추출하기
pos_comment_nouns = []
for cmt in pos_reviews["comment"]:
pos_comment_nouns.extend(okt.nouns(cmt))
print(pos_comment_nouns)neg_comment_nouns = []
for cmt in neg_reviews["comment"]:
neg_comment_nouns.extend(okt.nouns(cmt))
print(neg_comment_nouns)- 우선 시작은 명사만 담아 놓을 리스트 변수 선언해 준다.
4. 긍정 및 부정 리뷰 데이터에서 1글자는 모두 제외시키기
- 1글자인 명사는 뜻을 가질 수도 있지만 그렇지 않다고 판단되어 제외시키겠다.
* 긍정 및 부정리뷰 명사 데이터에서 1글자 모두 제외하기
pos_comment_nouns2 = [w for w in pos_comment_nouns if len(w) > 1]
print(pos_comment_nouns2)neg_comment_nouns2 = [w for w in neg_comment_nouns if len(w) > 1]
print(neg_comment_nouns2)
5. 긍정 및 부정 명사들의 빈도 분석
### 리뷰 명사들에 대한 워드카운트 라이브러리
from collections import Counter
* 긍정 및 부 명사 워드카운트 처리
pos_word_count = Counter(pos_comment_nouns2)
print(pos_word_count)neg_word_count = Counter(neg_comment_nouns2)
print(neg_word_count)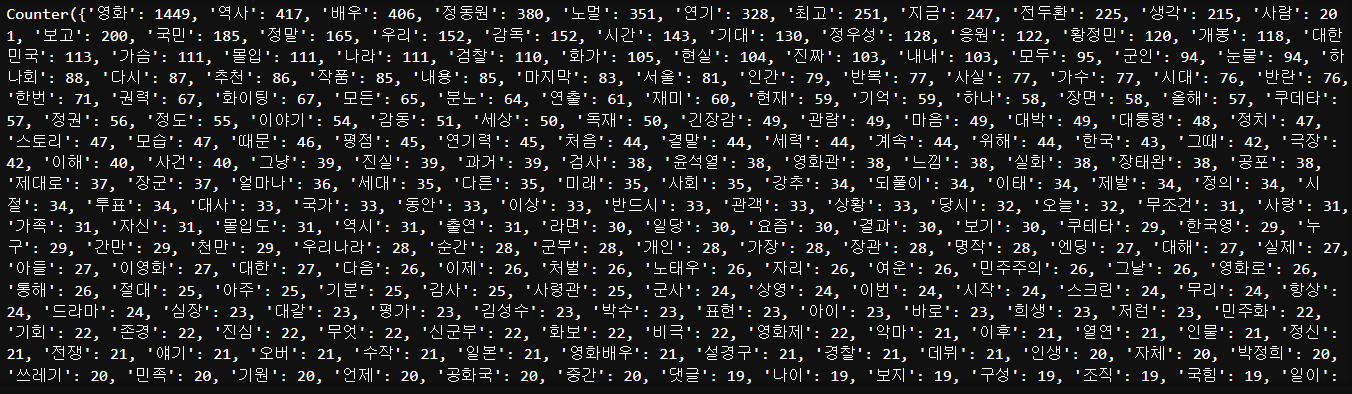
딕셔너리 타입으로 나온다.
6. 긍정 및 부정 워드카운트 상위 20개 단어만 추출
* 긍정 및 부정 -> 워드카운트 상위 20개 단어 추출
- count() => 지원하는 함수 -> 내림차순 함수 : most_commend(20)
--> 내림차순 후에 상위 20개 추출하는 함수임
pos_top_20 = {}
for k,v in pos_word_count.most_common(20):
pos_top_20[k]=v
print(pos_top_20)neg_top_20 = {k:v for k, v in neg_word_count.most_common(20)}
print(neg_top_20)for문을 쓰는 방식에 따라 위아래 형식 둘 다 가능.
7. 긍정 및 부정 상위 20 단어 빈도 비교
### 시각화 라이브러리
import matplotlib.pyplot as plt
### 폰트 설정라이브러리
from matplotlib import font_manager, rc
### 폰트설정
plt.rc("font", family="Malgun Gothic")
### 마이너스 기호 설정
plt.rcParams["axes.unicode_minus"] = False* 긍정=> 막대그래프를 이용한 빈도 시각화
plt.figure(figsize=(10,5))
### 제목넣기
plt.title(f"긍정 리뷰의 단어 상위 (20개) 빈도 시각화", fontsize=17)
### 막대그래프 그리기
for key, value in pos_top_20.items():
### 영화라는 단어는 의미가 없을 것으로 여겨짐
if key == "영화":
continue
plt.bar(key, value, color="lightgray")
### x,y축 제목 넣기
plt.xlabel("리뷰명사")
plt.ylabel("빈도(count)")
### x축 각도 조정
plt.xticks(rotation=70)
### 그래프 보기
plt.show()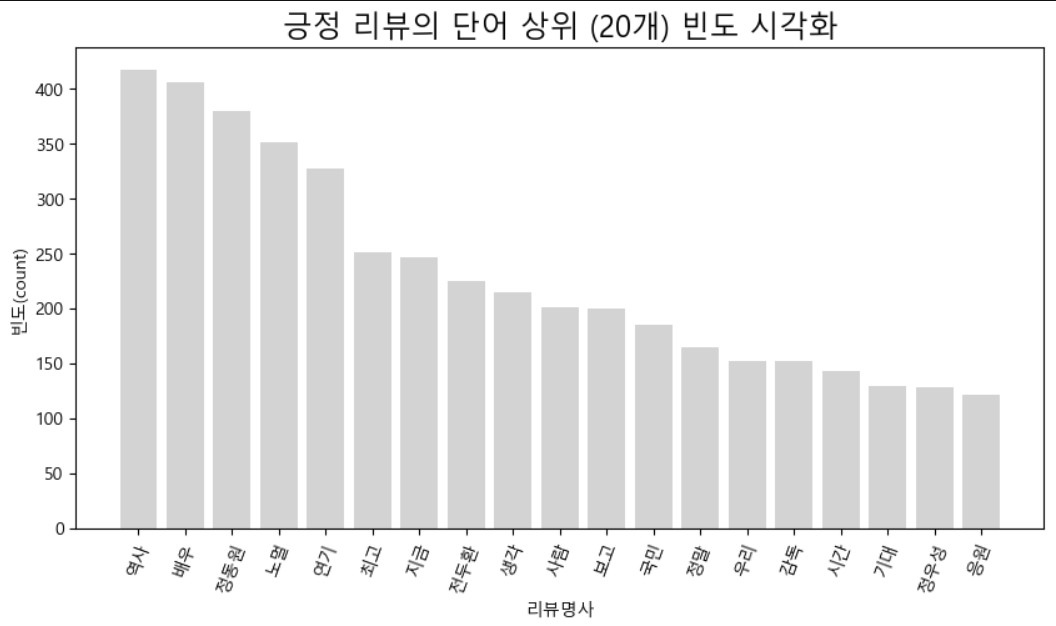
* 부정 막대그래프를 이용한 빈도 시각화
plt.figure(figsize=(10,5))
### 제목넣기
plt.title(f"부정 리뷰의 단어 상위 (20개) 빈도 시각화", fontsize=17)
### 막대그래프 그리기
for key, value in neg_top_20.items():
### 영화라는 단어는 의미가 없을 것으로 여겨짐
if key == "영화":
continue
plt.bar(key, value, color="blue")
### x,y축 제목 넣기
plt.xlabel("리뷰명사")
plt.ylabel("빈도(count)")
### x축 각도 조정
plt.xticks(rotation=70)
### 그래프 보기
plt.show()